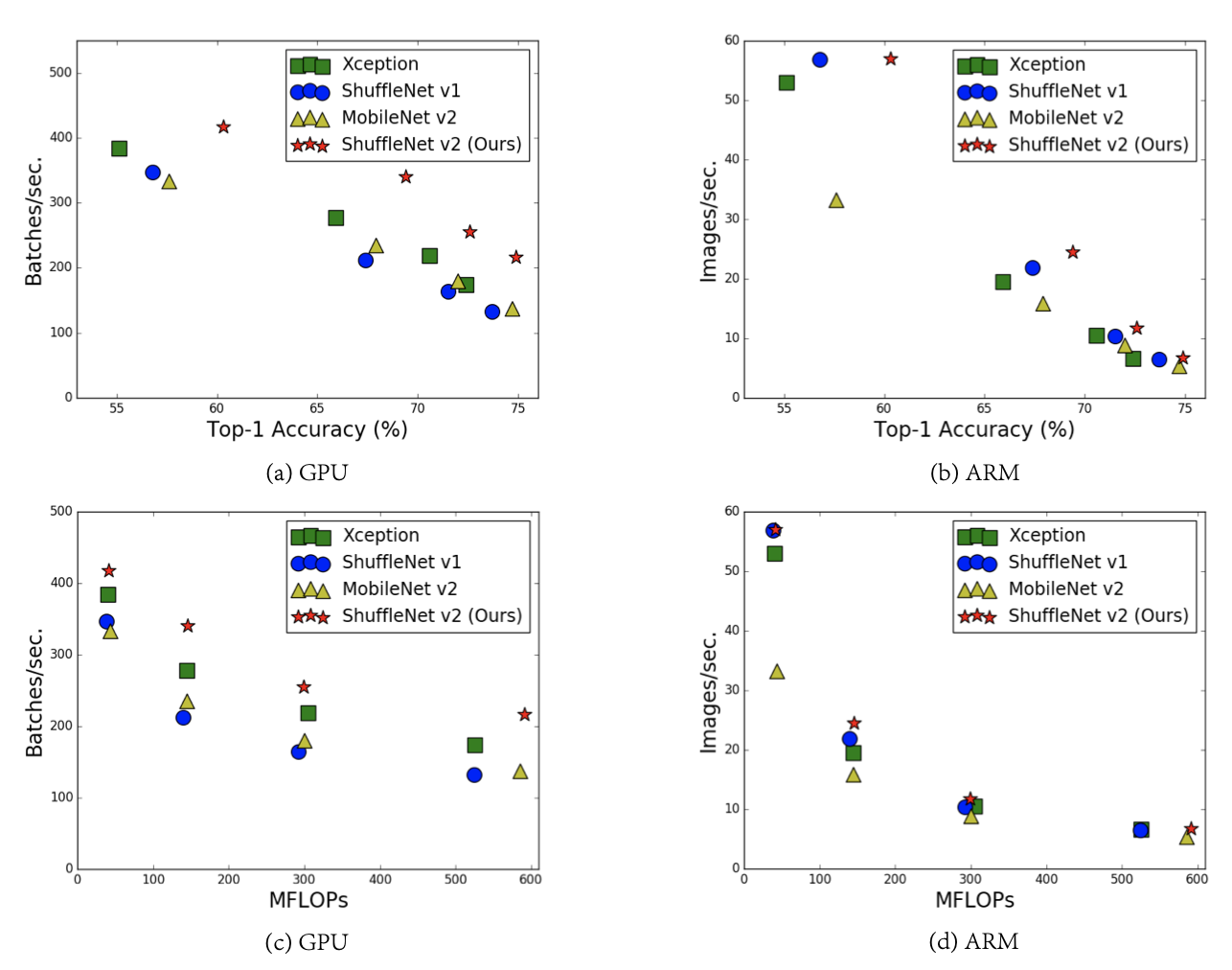
Introduction 본 논문은 기존 경량화 모델에서 고려됐던 metric인 FLOPs이 간접적인 메트릭임을 지적하며 직접적인 메트릭인 speed와 latency를 언급했다. 더불어 네트워크 디자인에 대한 가이드라인을 제시하며 이에 따라 업그레이드된 ShuffleNetV2를 제안한다. 기존의 경량화 모델들은 주로 depth conv, ptwise conv, group conv과 같은 tensor decomposition을 활용하여 FLOPs을 줄이는 걸 목표로 디자인했다. 이를 따르면 실제 기기에 올라갈 때 빨라질 것 같지만 그렇지 않다. FLOPs만을 고려하는 디자인은 sub-optimal한 디자인일 수 밖에 없다. 1) FLOPs에는 영향을 덜 끼치지만 speed에는 영향을 끼치는 팩터가 있기 때문..