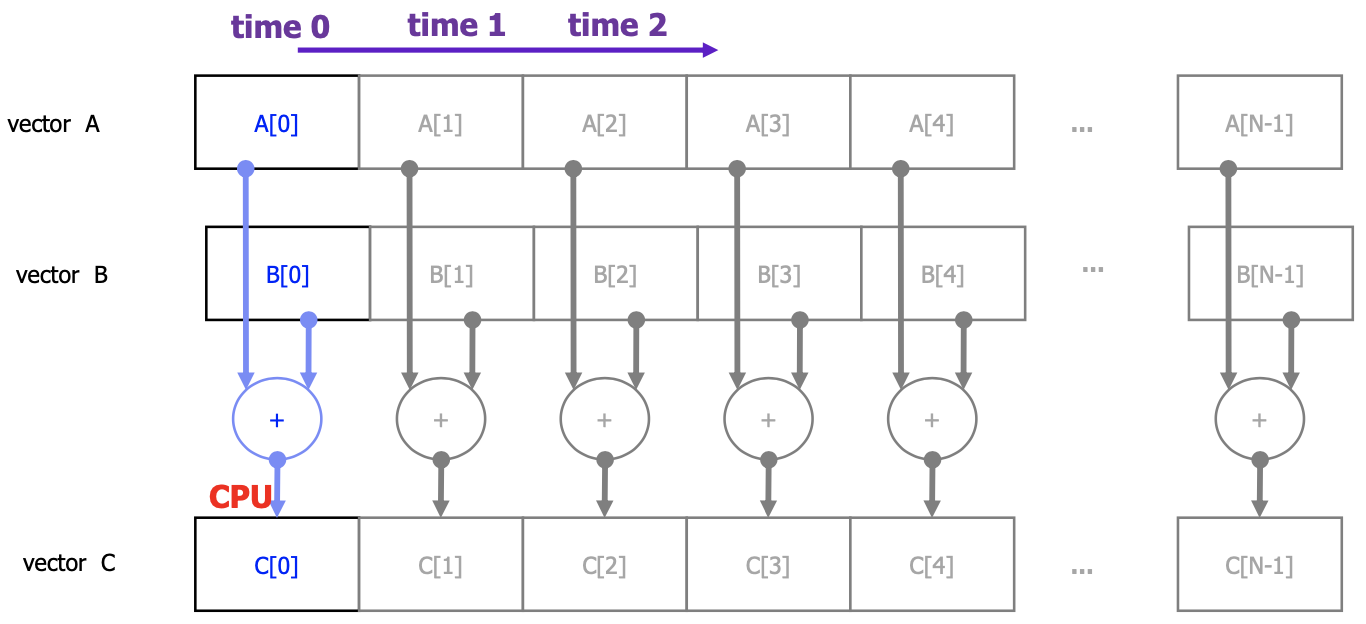
Instruction-level Parallelism (2) Dynamic Scheduling Limitations of simple techniques A major limitation issue and execution in-order instruction issue and execution 명령어가 프로그램 순서에 따라 issue되고 명령어가 파이프라인에서 stall되면 이후 명령어를 처리할 수 없다. 명령어 j가 long-running 명령어 i에 종속성을 가지면, 명령어 j 이후에 실행될 모든 명령어들은 i가 끝나가 j가 실행될 때까지 stall돼있어야 한다. Simple techniques은 약간의 data dependence stalls만 제거할 수 있다. 몇몇 dependence는 런타임까..