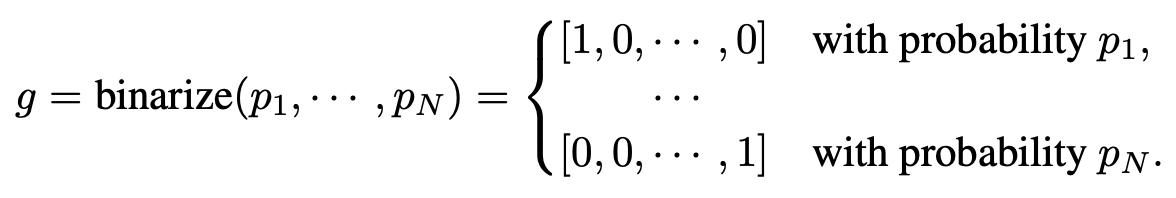ProxylessNAS: Direct Neural Architecture Search On Target Task And Hardware Problems To Solve 기존 cotroller를 사용하는 방식의 NAS는 많은 GPU Time이 걸렸다. 이를 해결하기 위해 NAS의 objective function을 differentiable하게 만들어 archtecture search를 한 시도는 GPU Time은 많이 줄일 수 있었으나 GPU Memory 사용이 많았다. 더불어 ImageNet과 같은 큰 데이터셋에 대해서는 시간이 오래 걸려 proxy를 사용하여, network를 evaluation을 하려는 시도가 있었으나 proxy task에 evaluation된 아키텍쳐가 target task에서 성..