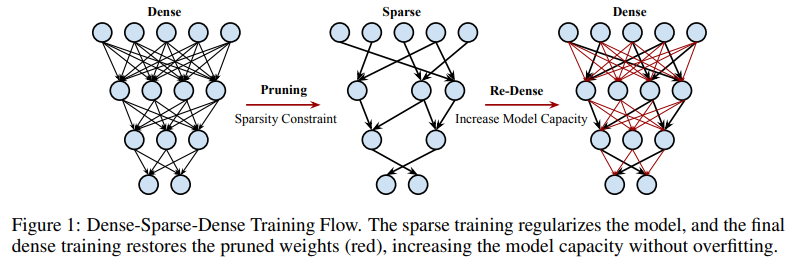
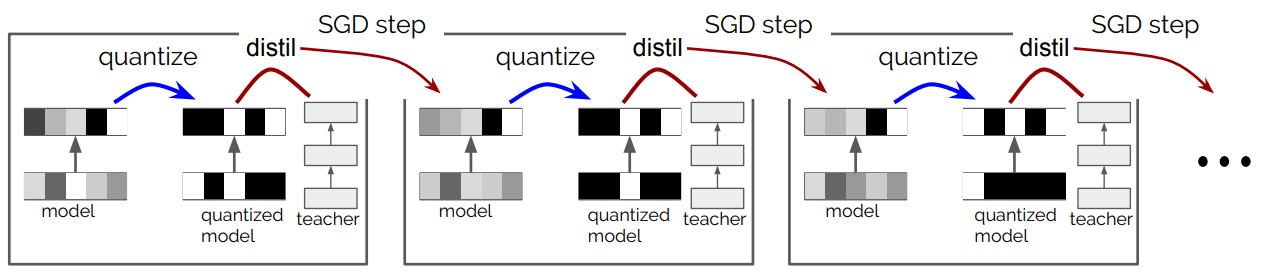
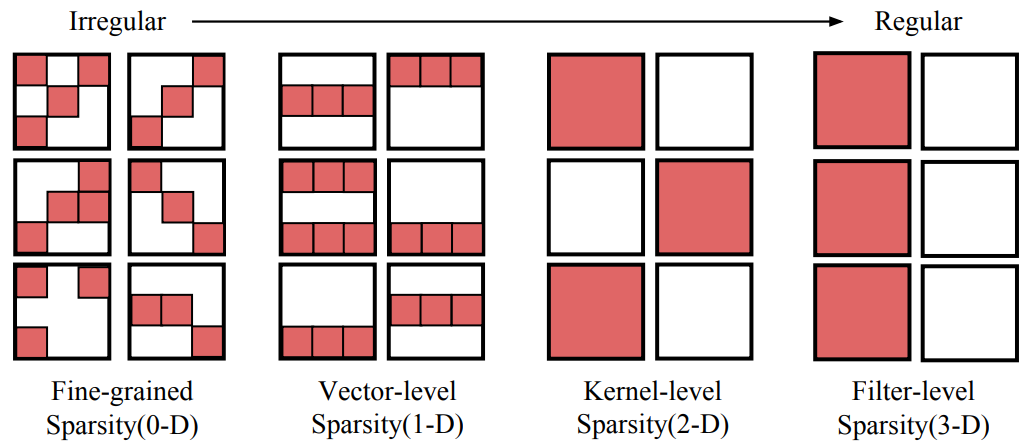
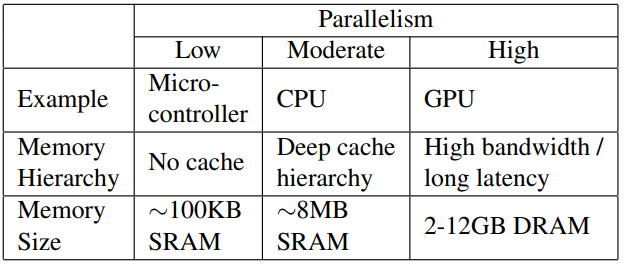
Paper Link: https://arxiv.org/abs/1810.02340 Github: https://github.com/namhoonlee/snip-public Introduction 본 논문은 ICLR 2019에서 발표된 weight pruning 논문입니다. 본 논문에서는 기존의 pruning 기법들이 휴리스틱에 근거한 hyperparameter를 사용하거나 iterative하게 pruning하는 것을 지적하며, training이전에 connection sensitivity를 계산하여 이를 기반으로 single-shot pruning하는 것을 제안합니다. 실제로 origianal network보다 efficient한 subnetwork를 얻기 위해서는 꼭 학습이 필요한 것인가? 그리고, 프루..