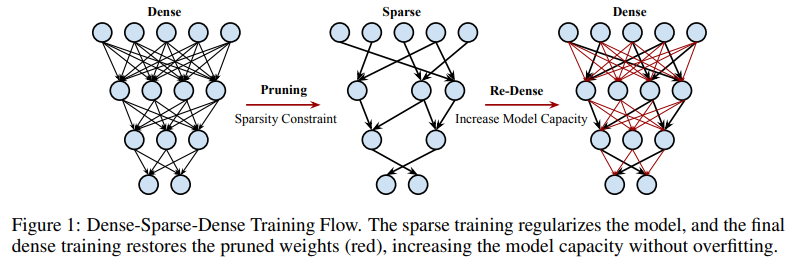
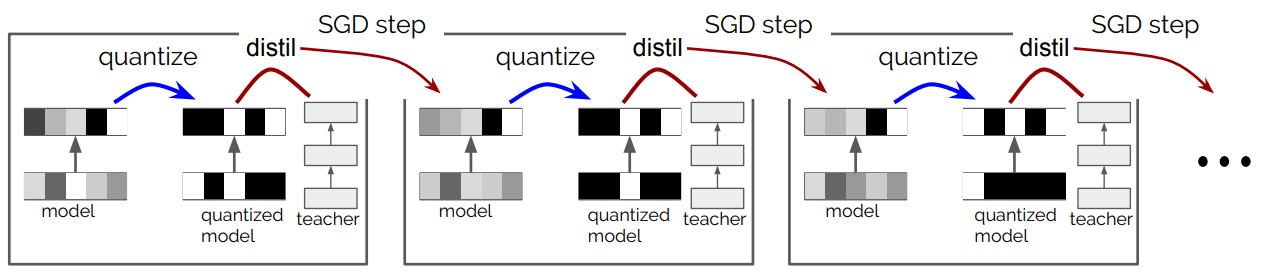
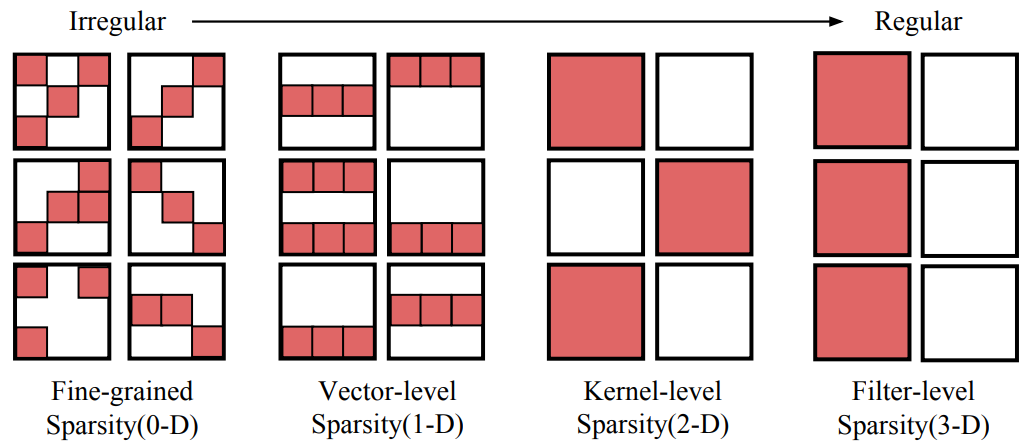
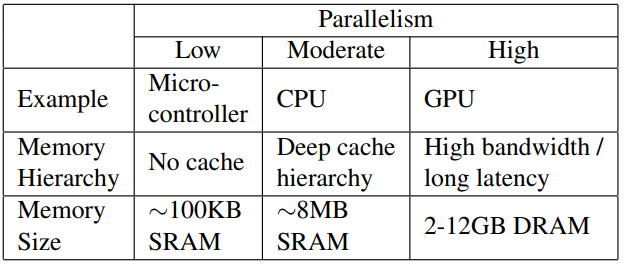
Gate Decorator: Global Filter Pruning Method for Accelerating Deep Convolutional Neural Networks Network Pruning via Transformable Architecture Search AutoPrune: Automatic Network Pruning by Regularizing Auxiliary Parameters Global Sparse Momentum SGD for Pruning Very Deep Neural Networks Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask One ticket to win them all: generalizing lot..