이전 포스팅에서 'Memory Hierarchy'를 배웠습니다. 계층도를 살펴보면 L1, L2 Cache 이런게 나오는데 'Cache Memory'는 뭘까요?

Cache Memory
: 속도가 느린 메인 메모리의 접근 시간을 향상시키기 위해 일시적으로 데이터를 갖고 있는 작지만 빠른 메모리를 이야기합니다. 캐시 메모리는 'Locality'를 활용하기 위한 구조를 갖고 있습니다. 그리고 낮은 계층의 메모리보다 크기가 작습니다. 즉, L1 Cache는 L2 Cache의 크기보다 작고, L2 Cache는 L3 Cache보다 크기가 작습니다.
그림에서 알 수 있듯이 L1 Cache는 크기가 매우 작으며 내부는 메모리의 텍스트 영역을 다루는 Instruction Cache와 이외의 영역을 다루는 Data Cache로 나뉩니다. L2 Cache는 코어가 공유하는 캐시이며, L3 Cache는 보다 크며, 멀티 코어 시스템에서 여러개의 코어가 공유하는 캐시를 일컫습니다.
캐시는 SRAM으로, 주소를 키값으로 사용하는 하드웨어로 구현한 해시 테이블입니다. 그래서 주소값을 갖고 있으면 이에 해당하는 블록의 데이터에 접근이 가능합니다. 블록의 갯수와 크기는 캐시마다 다른데, 이것이 캐시의 크기를 결정합니다. 이제 메인 메모리에서 캐시에 매핑을 해서 데이터를 전달해야 합니다. 이때 방법은 Direct-mapped Cache, Assocative Cache, Set Associative Cache 총 세가지가 있습니다.
Direct-mapped Cache
: 이 방법에서는 캐시의 위치는 메모리 주소를 인덱싱하여 결정합니다. 모든 블록은 캐시 메모리의 오직 한 위치에만 매핑될 수 있는데, 이를 매핑하는 인덱싱 방법은 다음과 같습니다.
Index = (Block Address) mod (# of cache blocks)

캐시의 블록 갯수가 8개이기 때문에, 메모리의 2, 10, 18번째에 있는 블록들이 캐시 메모리에 매핑된 것을 확인할 수 있습니다. 하지만 이렇게 되면 문제가 생깁니다. 여러 블록들이 캐시의 하나에 매핑됐기 때문에 블록의 정확한 주소를 알 수가 없습니다. 예를 들어서, 001에 매핑된 블록은 00001, 01001, 10001, 11001에 온것일 수 있습니다. 이를 해결해주기 위해 우리는 태그라는 것을 도입해줍니다. 태그는 주소의 상위에 있는 비트를 이야기합니다.
Tag in example
00001 > 00001 (태그: 00)
01001 > 01001 (태그: 01)
10001 > 10001 (태그: 10)
11001 > 11001 (태그: 11)

인덱스와 태그를 같이 이용하면 블록이 어디서 왔는지 알 수 있습니다.
위에서 캐시에서 주소를 인덱스, 태그로 나누어 메모리에 캐시를 매핑하였습니다. 실제로 캐시에서 주소는 태그, 인덱스, 오프셋 세가지로 나뉩니다. 캐시 메모리가 32비트라고 가정했을 때, 인덱스 파트는 10비트가 됩니다. 메모리에서 2^n개 블록의 모든 인덱스를 표현하기 위해서는 n개의 비트가 필요하기 때문입니다. 정확한 정의는 다음과 같습니다.
Offset part: log_2 (block size in bytes) = 2
Index part: log_2 (cache size/block size) = 10
Tag part: # of address bits - (# of index bits + # of block bits) = 20

1. 인덱스를 통해서 태그 어레이에 접근한다.
2. 태그 어레이의 값과 태그를 같은지 비교한다.
3. Vailid bit값과 2번에서 비교한 값에 AND 연산을 하여 Hit나 Miss를 발생시킨다.
4. 데이터를 전송시킨다.
> 3, 4는 병렬적으로 처리한다. 만약 3번에서 Miss가 발생하면 4번에서 이미 데이터를 전송하였기 때문에 리소스에 낭비가 생긴다.
Direct-mapped Cache는 간단하고 탐색이 쉽다는 장점이 있지만, Hit ratio가 낮다는 단점이 있습니다. 다음과 같은 경우를 생각해보면 됩니다.
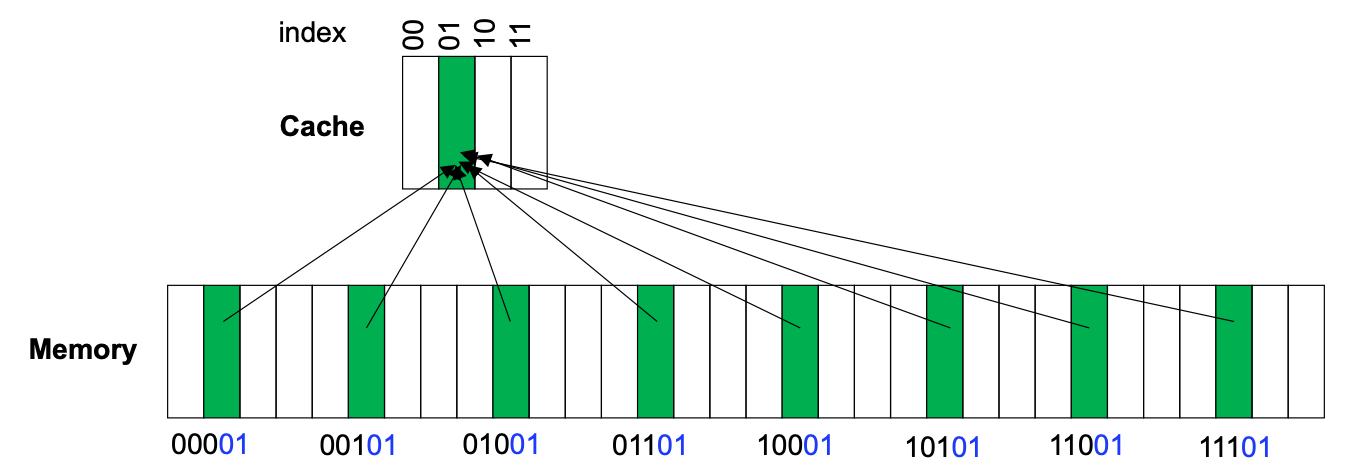
이 경우에는 요청되는 블록이 모두 같은 인덱스를 가리키고 있기 때문에 캐시를 빈번하게 바꿔야 할 것입니다. 그러면 Hit rate는 0이 되겠지요. 이를 해결해주기 위해서는 태그 어레이와 데이터 어레이를 여러개 만들어 해결할 수 있습니다. 이 방법을 'Associative Cache'라고 부릅니다. 이 방법에는 'Fully Associative Cache'와 'Set Associative Cache' 두가지가 있습니다.
Fully Associative Cache
: 블록이 캐시의 어디든 배치될 수 있는 방법을 이야기합니다. 이때 캐시는 인덱스를 갖지 않고, 태그만을 갖고서 탐색을 합니다. Hit rate이 높지만, 병렬적으로 검사를 해야하기 때문에 회로가 복잡하다는 단점이 있습니다.
Set Associative Cache
: Direct-mapped Cache와 Fully Associative Cache의 장점을 동시에 취하기 위해 고안된 방법입니다. n-way mapping을 통해서 탐색하는데, 여기서 n은 set index를 가리킵니다. 그리고 set index는 다음과 같습니다.
Set Index = (Block Address) mod (# of sets in the cache)
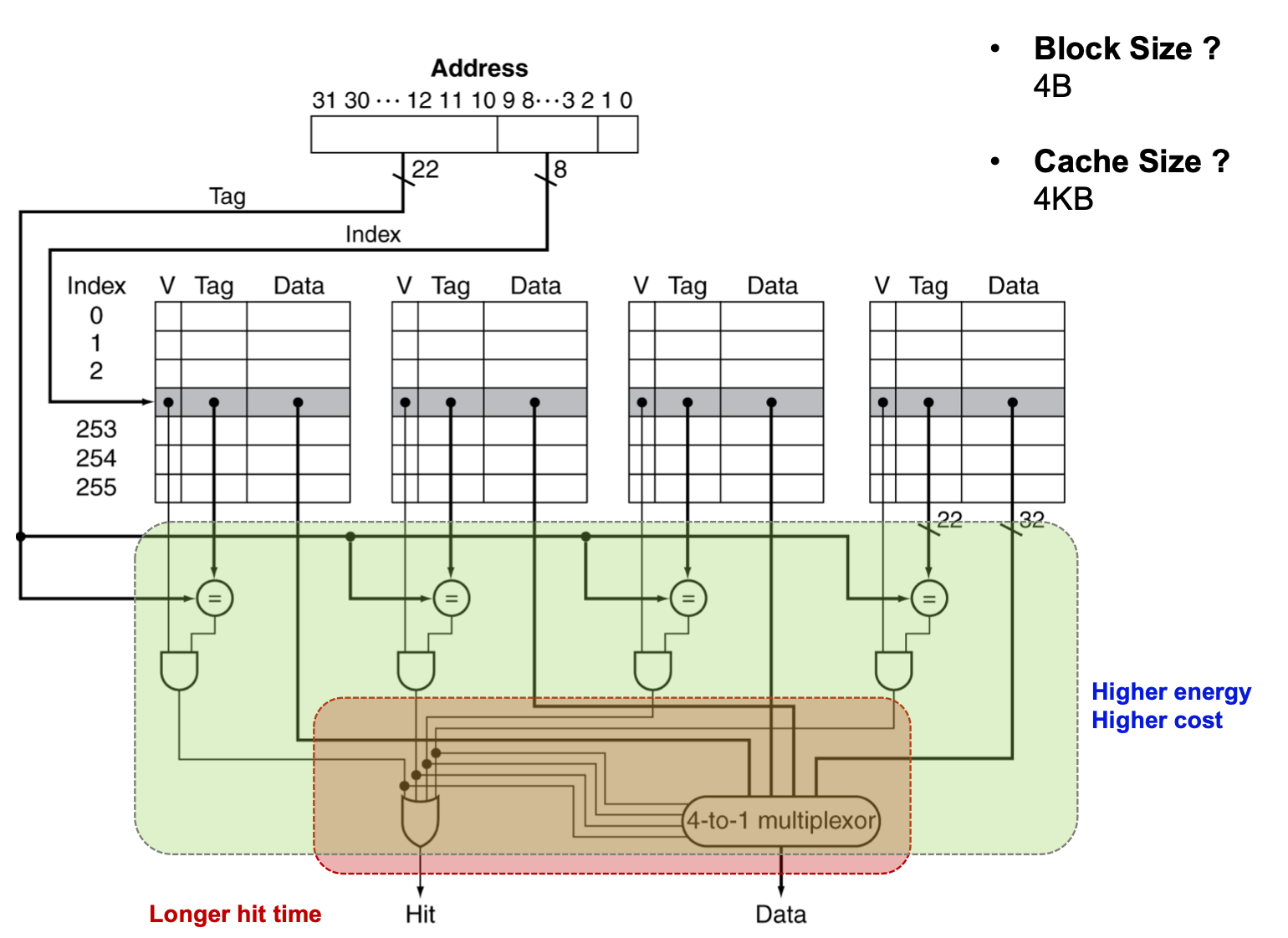
1. 인덱스를 통해 태그 어레이에 접근한다.
(4-way기 때문에 한번에 접근할 수 있는 태그가 4개이다.)
2. 태그 어레이의 값과 태그가 같은지 비교한다.
3. Vailid bit값과 2번에서 비교한 값에 AND 연산을 하여 Hit나 Miss를 OR 게이트로 보낸다.
4. 이를 OR 연산하여 최종적으로 Hit인지 Miss인지 보낸다.
5. 데이터를 전송한다.
> 4, 5는 병렬적으로 처리한다. 4에서 Miss가 나면 교체 정책에 따라 블록 중 하나에 데이터를 작성한다.
Associative Cache는 Hit rate를 높일 수 있다는 장점이 있지만, 몇가지 단점이 있습니다.
1. Set안에 있는 모든 태그를 읽어야하기 때문에 에너지 소모가 크다.
2. Set안에 있는 모든 태그를 비교해야하기 때문에 히트 타임이 길다.
3. 비교 연산과 멀티플렉서를 사용하기 때문에 설계가 복잡해져 H/W cost가 크다.
이러한 단점에도 불구하고, Hit rate을 높일 수 있기 때문에 현대의 캐시는 Associative Cache를 사용한다고 합니다.
'컴퓨터 > 컴퓨터구조특론' 카테고리의 다른 글
| [ACA] Improving Cache Performance (0) | 2020.04.13 |
|---|---|
| [ACA] Memory Hierarchy and Caches (4) (0) | 2020.04.12 |
| [ACA] Memory Hierarchy and Caches (3) (1) | 2020.04.12 |
| [ACA] Memory Hierarchy and Caches (1) (0) | 2020.04.10 |
| Fundamentals (0) | 2020.04.05 |