반응형
1. Fundamentals of CUDA
1.1 History
1.1.1 3D Graphics Pipeline

- 3D 이미지를 만들어낼 때 다음과 같은 단계를 거친다.
- 3D mesh를 vertex processing을 통해 triangles in screen space를 만든다.
- Rasterization을 통해 여러 개의 triangles을 픽셀로 만든다.
- Raster Operations를 통해 Texture filtering을 하여 각 픽셀에 색상을 입힌다.
- Fragment processing을 통해 3D 이미지를 출력한다.
- 1세대
- 모든 스테이지를 하드웨어로 구현했다.
- 고정된 데이터 흐름을 가진다.
- 2세대
- 하드웨어가 특정 기능을 하지만 어느정도 설정할 수 있었다. -> 특정 모드를 지원
- 시간이 지남에 따라 모드를 점차 늘렸다.
- 모든 기능을 하드웨어로 구현하다보니 최적화하기 어려웠다.
- 개발자 잎장에서는 유연성이 부족했다.
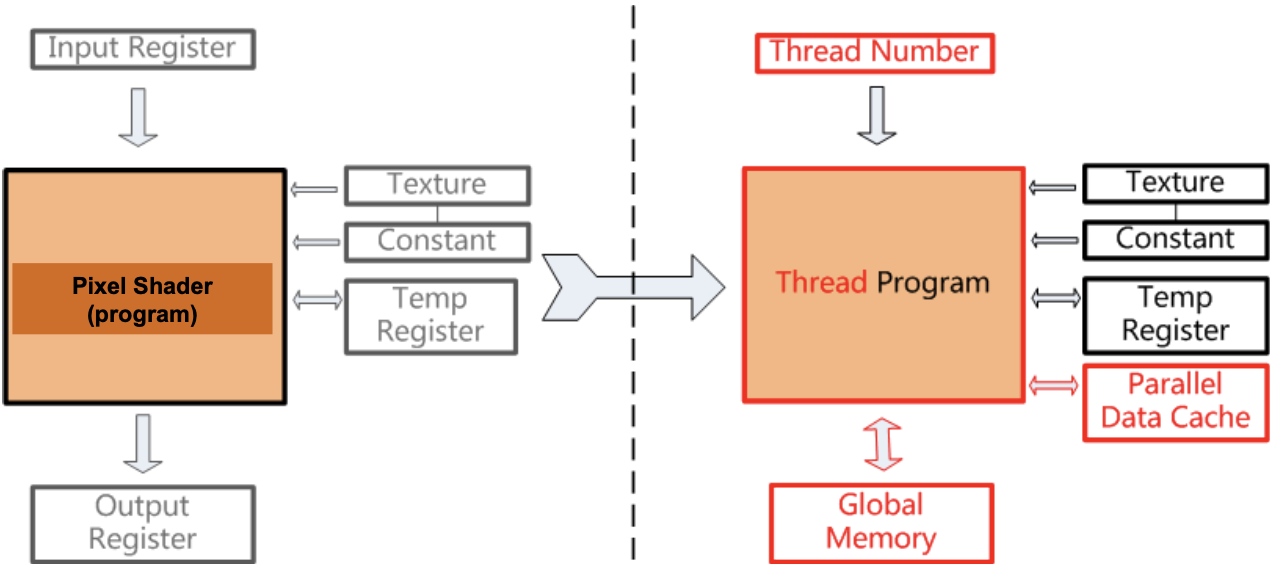
- 3세대
- Vertex & pixel 처리가 프로그래밍 가능하도록 바뀌었다.
- 'Shader'실행을 효율적으로 처리할 수 있게끔 GPU가 발전하게 됐다.
1.1.2 Before CUDA
- GPU를 일반적인 병렬 처리 애플리케이션을 처리하기 위해 사용하기 시작했다.
- 프로그램을 그래픽 처리에 맞게끔 바꿔줬어야 했다.
- 데이터를 이미지화 해야했다. ("texture maps")
- 알고리즘을 그래픽 처리 방식으로 바꿔줘야했다. ("rending passes")
- 단점
- 배우기 어려웠다.
- 그래픽스 API 오버헤드가 컸다.
- API가 그래픽에 너무 특화됐다. 그래서 명령어 종류도 많지 않았다.
- 메모리 레이아웃과 모델 접근에 제약이 많이 따랐다.
- 스레드간 커뮤니케이션이 부족했다.
- 입력/출력 데이터의 저장 공간이 부족했다.
- 로컬 스토리지가 부족했다.
- Vertex/Pixel Shader간 하드웨어 리소스의 사용률이 떨어지는 문제가 있었다.
1.2 What is CUDA?
1.2.1 CUDA Introduction
-
CUDA: Compute Unified Device Architecture
- 병렬처리를 위한 애플리케이션 프로그래밍 인터페이스 모델
- 쿠다를 사용하면 그래픽스 API를 사용하지 않고 병렬 컴퓨팅을 할 수 있다.
-
Targeted Software stack
- Lirary, Runtime, Driver
-
장점
-
SW: C와 유사한 형태로 GPU 프로그램을 만들 수 있다.
-
확장성있는 데이터 병렬 실행/메모리 모델을 제공해준다.
-> 병렬 프로그램을 실행할 때 스레드 갯수를 다양하게 설정할 수 있고, 쿠다로 만든 병렬 프로그램은 다른 쿠다를 지원하는 GPU에서 처리할 수 있는데, 코어 갯수가 더 많은 경우 더 빠르게 처리 가능하다.
-
C의 문법만 잘 알고 있으면 GPU 프로그램을 짤 수 있다.
-
-
HW: 완전히 일반적인 데이터 병렬적인 아키텍쳐를 설계할 수 있다.
-
-
특징
- Heterogeneous - 순차/병렬 코드가 섞여있는 형태
- Scalable - 계층적인 스레드 실행 모델을 갖고 있다.
- Accessible - C언어를 잘 알고 있으면 접근성이 좋다.
- 쿠다 전/후 -> 범용 아키텍쳐로 바뀌게 됐다.
Review: Heterogeneous Computing
- 하나 이상의 프로세서나 코어를 사용하여 계산하는 것을 말한다.
- CPU는 순차적인 부분을 처리할 때 사용
- GPU는 병렬적인 부분을 처리할 때 사용
1.2.2 Simple CUDA Model

-
Host: CPU + main memory (host memory)
-
Device: GPU + video memory (device memory)
-
GNU gcc: linux c compiler
-
nvcc: NVIDA CUDA compiler
- nvcc로 쿠다 코드를 컴파일
- GNU gcc로 nvcc를 컴파일하여 CPU
1.2.3 CUDA Program Execution Scenario
- "host+device" 코드로 구성되어 있다.
- 순차적이거나 일부 병렬적인 부분은 host code에서 실행된다.
- 높은 병렬성을 갖는 부분은 device code에서 실행된다.
- Execution Scenario
- Step 1: host code
- 순차 실행: 데이터를 읽는다.
- 병렬 실행을 준비한다.
- host memory에서 device memory로 데이터를 복사한다.
- Step 2: device code (kernel)
- 병렬 처리
- device memory에서 device memory로 데이터를 읽고 쓴다.
- Step 3: host code
- device memory에서 host memory로 데이터를 복사한다. (연산의 결과)
- 순차 실행: 연산 결과를 출력
- Step 1: host code
1.3 Device Global Memory and Data Transfer

- GPU cores는 "global memory"를 공유한다. (device memory)
- DRAM이 주로 global memory로 사용된다.
- device에서 커널을 실행하기 위해서 네 단계를 거처야 한다.
- device에서 global memory를 할당한다.
- host memory에서 할당받은 global memory에 데이터를 전송한다.
- 연산 결과를 device memory에서 host memory로 전송한다.
- global memroy를 해제한다.
1.3.1 Memory Spaces
- CPU, GPU는 분리된 메모리 공간을 갖고 있다.
- 데이터 버스를 통해 데이터는 이동한다.
- GPU의 메모리를 할당/설정/복사 하기 위해 함수를 사용한다.
- C언어의 함수와 유사하다.
- 포인터를 사용할 건데, 포인터는 주소일 뿐이다.
- 주소만 보았을 때 CPU/GPU 중 어느 곳의 주소인지 알 수 없다.
- GPU에서 CPU pointer를 사용하면 crash가 발생한다. (역도 같음)
1.3.2 CPU/GPU Memory Allocation/Release
-
Host (CPU) manages host (CPU) memory:
-
void* malloc (size_t nbytes)
-
void* memset (void* pointer, int value, size_t count)
-
void free (void* pointer)
-
-
Host (CPU) manages device (GPU) memory:
- cudaMalloc (void** pointer, size_t nbytes) (더블 포인터를 넘겨주는 것에 유의)
- cudaMemset (void* pointer, int value, size_t count)
- cudaFree (void* pointer)
-
CUDA function rules
- 모든 라이브러리 함수는 'cuda'로 시작한다.
- 대부분은 에러 코드를 리턴하도록 되어있다.
-
CUDA Malloc
- cudaError_t cudaMalloc( void** devPtr, size_t nbytes );
- 첫 번째는 포인터 변수에 대한 포인터 값
- 시작 주소를 'devPtr'에 저장
- 메모리가 0으로 초기화되진 않는다.
- 정상적으로 할당했으면 cudaSucces 그렇지 않으면 cudaErrorMemoryAllocation
- cudaError_t cudaFree( void* devPtr );
- devPtr가 가리키는 메모리 공간을 해제한다.
- cudaError_t cudaMalloc( void** devPtr, size_t nbytes );
-
CUDA mem set
- cudaError_t cudaMemset( void* devPtr, int value, size_t nbytes );
- nbytes만큼 devPtr이 가리키는 공간에 값을 할당해준다.
- cudaError_t cudaMemset( void* devPtr, int value, size_t nbytes );
-
Data Copy
- cudaError_t cudaMemcpy( void* dst, void* src, size_t nbytes, enum cudaMemcpyKind direction);
- CPU 스레드는 모든 데이터가 카피가 끝날 때까지 블록된다.
- 카피는 CPU에서 실행될텐데 memcpy를 할 때까지 다른 일은 멈추게 된다.
- 메모리 카피가 자주 일어나면 쿠다 프로그램 전체가 많이 느려지게 된다.
- dst: 데이터를 카피할 메모리 공간의 시작주소
- src: 카피할 데이터가 담겨져 있는 메모리 공간의 주소
- size_t: 카피할 데이터의 크기
- direction: 방향
- 이전 쿠다 콜이 끝날 때까진 카피를 시작하지 않는다.
- CPU 스레드는 모든 데이터가 카피가 끝날 때까지 블록된다.
- host -> host: memcpy (in C/C++)
- host -> device, device -> device, device -> host: cudaMemcpy (CUDA)
#include <iostream> int main(void) { // host-side data const int SIZE = 5; const int a[SIZE] = { 1, 2, 3, 4, 5 }; // source data int b[SIZE] = { 0, 0, 0, 0, 0 }; // final destination // print source printf("a = {%d,%d,%d,%d,%d}\n", a[0], a[1], a[2], a[3], a[4]); // device-side data int* dev_a = 0; int* dev_b = 0; // allocate device memory cudaMalloc((void**)&dev_a, SIZE * sizeof(int)); cudaMalloc((void**)&dev_b, SIZE * sizeof(int)); // copy from host to device cudaMemcpy(dev_a, a, SIZE * sizeof(int), cudaMemcpyHostToDevice); // copy from device to device cudaMemcpy(dev_b, dev_a, SIZE * sizeof(int), cudaMemcpyDeviceToDevice); // copy from device to host cudaMemcpy(b, dev_b, SIZE * sizeof(int), cudaMemcpyDeviceToHost); // free device memory cudaFree(dev_a); cudaFree(dev_b); // print the result printf("b = {%d,%d,%d,%d,%d}\n", b[0], b[1], b[2], b[3], b[4]); // done return 0; } - cudaError_t cudaMemcpy( void* dst, void* src, size_t nbytes, enum cudaMemcpyKind direction);
-
실행 결과
- 소스 코드를 컴파일한다.
- nvcc memcpy.cu -o ./memcpy
- ./memcpy를 실핸한다.
- a = {1,2,3,4,5}
- b = {1,2,3,4,5}
- 소스 코드를 컴파일한다.
반응형
'컴퓨터 > 대규모병렬컴퓨팅' 카테고리의 다른 글
| [MPC] 3. CUDA Thread (1) (0) | 2020.12.24 |
|---|---|
| [MPC] 2. Fundamentals of CUDA (2) (0) | 2020.12.22 |
| [MPC] 0. GPU Architecture (0) | 2020.12.16 |