Way Prediction (to reduce hit time)

Idea: 다음 캐시에 어떤 way나 block이 사용될 지 예측하자.
- Set-associative cache는 블록을 묶어서 캐시 미스를 줄였지만 태그 매칭하는 것이 오버헤드가 된다. 만약에, 다음 캐시에 어떤 way나 block이 사용될 지 예측하여 캐싱을 해두면 성능 향상을 가져올 수 있을 것이다.
1. 예측이 맞다면, hit time을 줄일 수 있을 것이다. 그리고 다른 엔트리를 훑어보지 않아도 되기 때문에 에너지 소모가 적어진다.
2. 예측이 틀리면, 다른 엔트리를 확인해야 하기 때문에 hit time이 늘어날 것이다.
실행하는 프로그램의 지역성(locality)이 높아서 어떤 way나 block이 사용될 지 쉽게 예측할 수 있다면, 그 way만 접근해서 읽어와 hit time도 줄일 수 있고, way 하나만 접근하기 때문에 에너지 소모를 줄일 수 있는 방법이다.
이를 구현하기 위해서는 데이터 어레이의 각 블록에 predictor bit을 추가하여, 캐시 액세스할만한 것을 정책(policy)에 따라 예측하는 과정이 필요하다.
Pipelined Cache Access (to increase cache bandwidth)
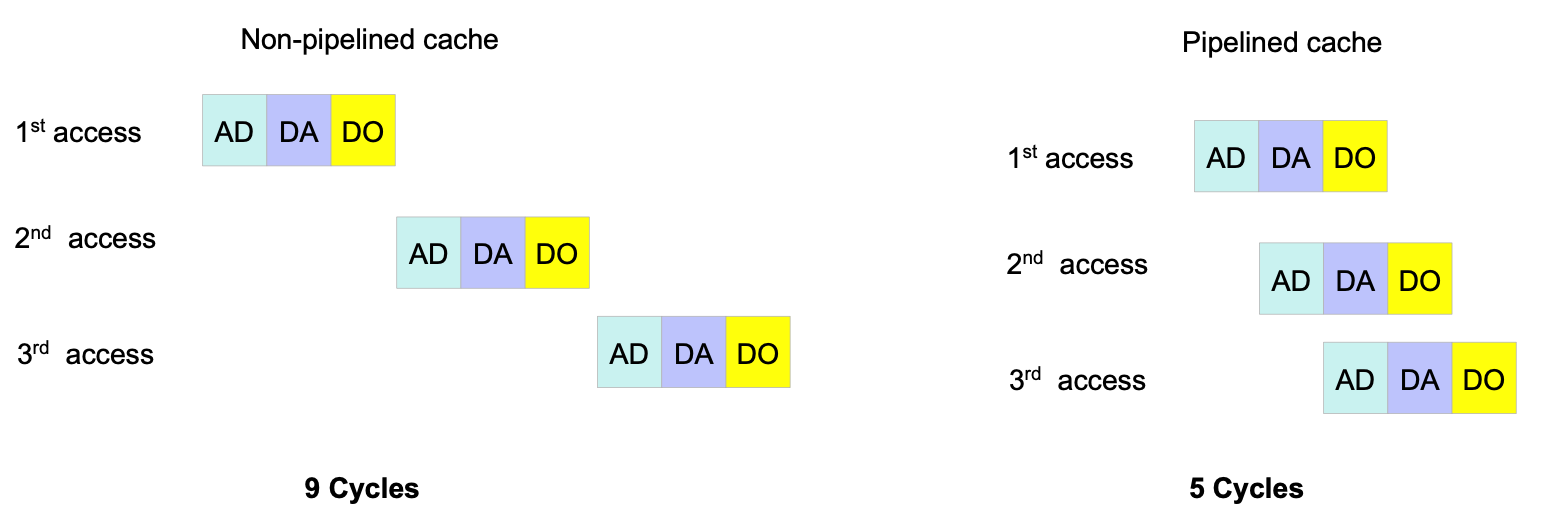
Idea: 긴 캐시 액세스를 오버래핑(overlapping)하여 bandwidth를 늘리자.
- CPU에서 fetch > decode > read > execute는 하나의 명령어 주기(instruction cycle)다. 한 명령어 주기를 도는 동안, 다른 명령어는 주기를 돌지 않으면, 그만큼 processing unit이 일을 하지 않기 때문에 성능 향상을 기대할 수 없다. 이를 위해 명령어 주기를 오버래핑하는 파이프라이닝을 했는데, 이를 모티브로 캐시 액세스에도 파이프라이닝을 적용한 방법이다. 캐시 액세스는 address decode + tag matching > data access > data out과 같은 과정을 거치는데, 이를 오버래핑한다.
1. 하지만, 브랜치를 잘못 예측해서 잡으면 미스 패널티가 증가하는 단점이 있다.
2. 그리고 캐시의 액세스 타임 자체는 줄이지 못한다.
Non-blocking Caches (to increase cache bandwidth)
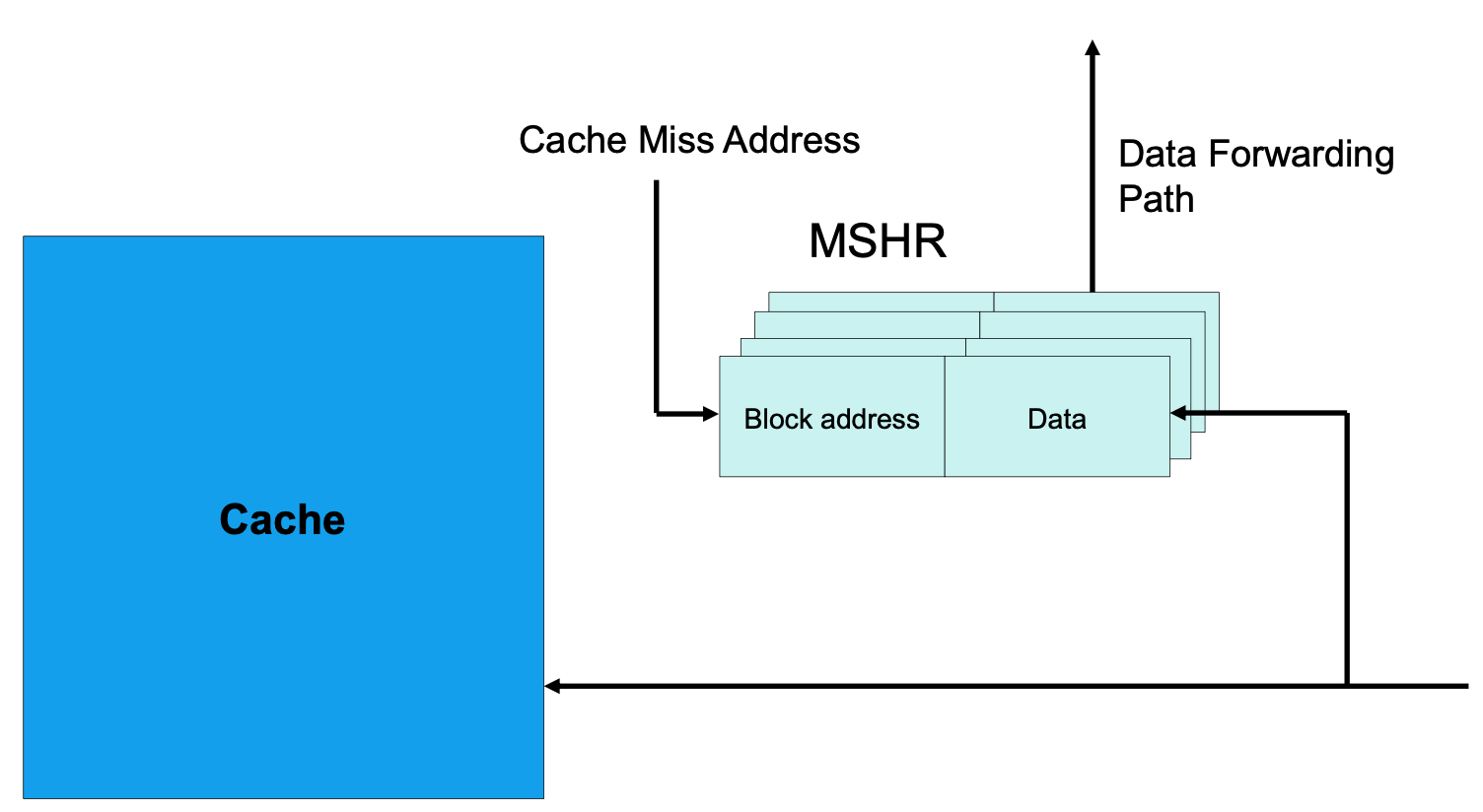
Idea: 캐시 미스 동안에, 데이터 캐싱을 하자.
- 프로세스가 연산을 하기 위해서 캐시에 메모리 요청을 보낸다. 그런데 캐시에 데이터가 없는 경우, 캐시 미스가 나는 경우에는 두가지 옵션이 있다.
1. 메인 메모리에서 데이터를 읽어올 때까지 기다린다.
2. 메인 메모리에서 데이터를 읽어오는 도중에 다른 리퀘스트를 캐시에 보낸다.
Non-blocking caches는 두번째 옵션을 채택한 방법이다. 메인 메모리에서 CPU까지 데이터를 가져오는데 200 clock cycles 이상이 걸리는데, 그동안 CPU가 아무 일도 하지 않고 있다면 성능 향상을 기대할 수 없다. 구현은 MSHR(Miss Status Holding Register)라는 것을 캐시와 메인 메모리 사이에 넣어 구현한다. 이는 블록의 주소와 데이터를 저장하는데, 캐시 미스가 난 정보는 MSHR에 저장하고 메인 메모리에서 트래킹을 하니까 캐시는 새로운 데이터를 받아서 처리할 수 있다. 이 방법은 최근 프로세서 설계에는 필수적으로 들어가는 방법이다. 파이프라이닝하는 것의 한 종류로 봐도 된다.
Multibanked Caches (to increase bandwidth)

Idea: 데이터에 동시에 접근이 가능하게끔 독립적인 뱅크(bank)로 캐시를 구현한다.
- 만약, 하나의 뱅크로 캐시를 구현했을 때 한번에 접근할 수 있는 데이터가 n개라고 하면, 두개의 뱅크로 캐시를 구현했을 때는 한번에 접근할 수 있는 데이터가 2n개가 된다.
Critical word first and early start (to reduce miss penalty)
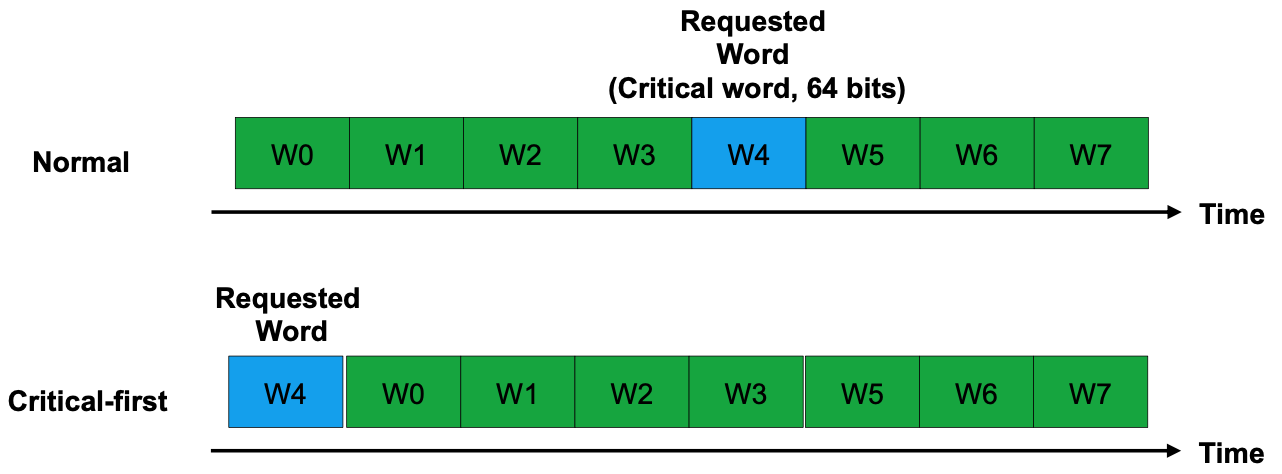
Idea: 캐시 블록 전체를 로드할 때까지 기다리지 말고 요구한 데이터만 가져오자.
- 캐시 블록의 사이이즈는 보통 64비트다. 프로세서가 캐시에 액세스를 할 때는 전체 블록을 요청하는 것이 아닌 8비트짜리 word를 요구한다. 그런데, 그것이 없다면 메인 메모리에서 64비트 블록을 다 읽어 오고나서 캐시에 저장한 뒤에 요청한 블록을 프로세서에 주고 연산을 수행하는데, 위에서 언급했듯이 메인 메모리에서 데이터를 읽어오는 것 자체가 오버헤드이고 필요한 데이터는 8비트 하나인데 블록 전체를 읽어오는 것도 효율적이지 않은 것 같다. 메모리에서 캐시를 읽어올 때는 시퀀셜하게(순차적으로) 읽어오는데, 이 방법은 요청한 데이터를 그 시퀀스의 첫번째에 배치하여 프로세서에게 데이터를 빠르게 전달한다.
Merged Write Buffer (to reduce miss penalty)

- CPU가 일을 하지 않을 때는 필요한 데이터가 레지스터에 없어서 프로세서가 연산을 수행하지 않을 때다. 그런데 write은 메모리에 데이터를 쓰는 것이고, 이는 성능에 영향을 미치지 않는다. 그런데 메모리가 데이터에 쓰여질 때까지 다른 명령어를 수행하지 못하니 성능이 나빠질 것이다. 이를 해결하기 위하여 캐시와 메모리 사이에 write을 위한 버퍼를 두어, 메모리에 쓰지 않고 버퍼에 미리 데이터와 데이터를 저장할 주소를 미리 쓰면 store instruction을 바로 종료시킬 수 있으니 성능 향상을 꾀할 수 있다.
Compiler Optimization (to reduce miss penalty)

- 컴파일러 최적화는 하드웨어 변경이 없어도 되는, 소프트웨어적인 방법이다. 이는 캐시를 더 효율적으로 사용할 수 있도록 소스 코드를 수정한다. 이때 인접한 캐시를 사용할 수 있게끔. locality를 잘 활용할 수 있는 방향으로 코드를 수정한다.
Hardware Prefetching
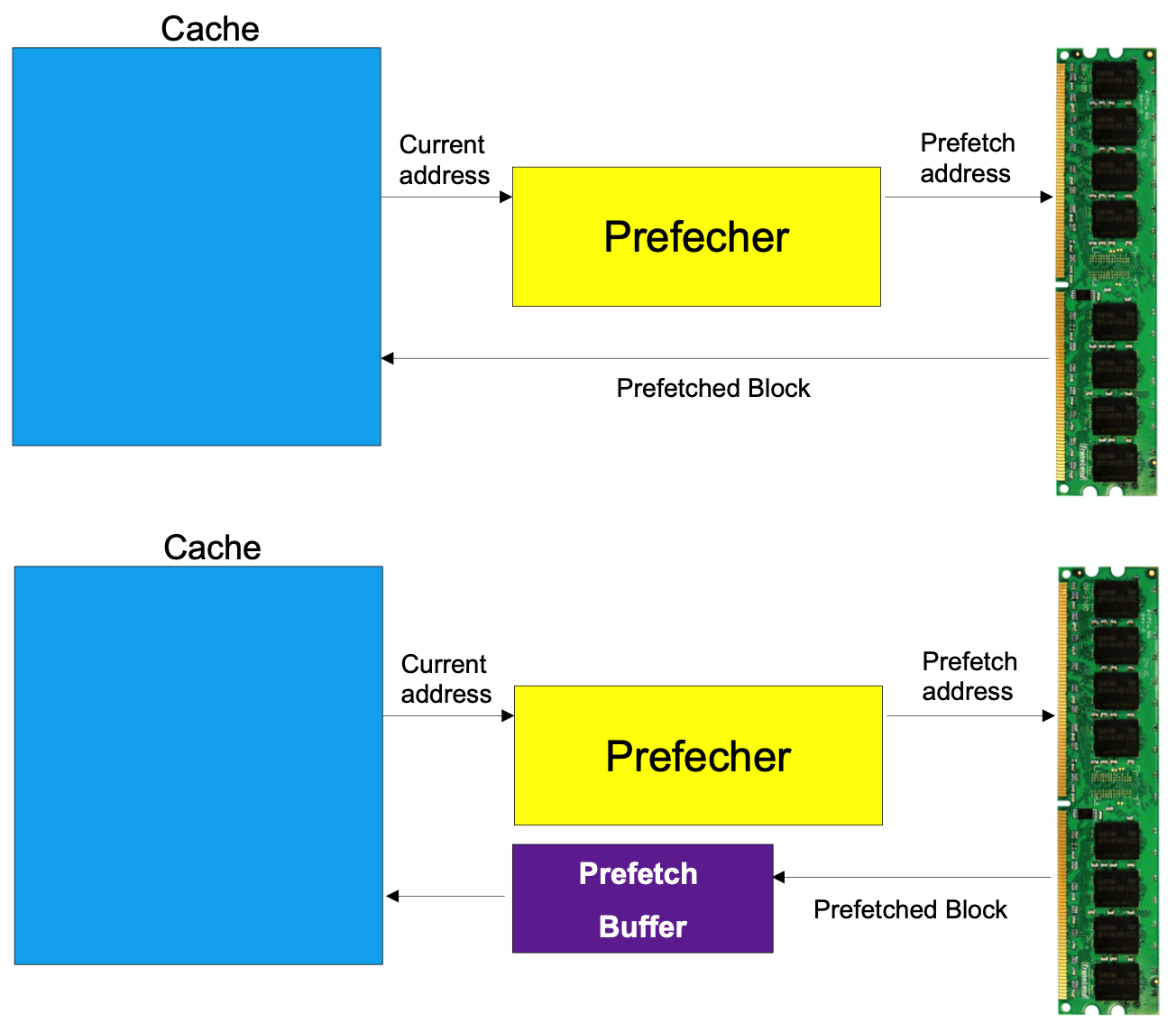
- Hardware Prefetching은 프로세서가 데이터를 요청하기 전에 미리 읽어오는 방법이다. 지역성을 활용하여, 하나의 데이터를 읽어오면 미리 다음 블록을 읽어온다. 지역성이 낮은 프로그램의 경우에는 성능이 안좋아질 수도 있다. 지역성이 낮아 미리 읽어온 인접한 주소의 데이터가 쓰이지 않는다면 캐시 미스가 나기 때문이다. 그리고 이 경우에는 불필요한 데이터를 읽어온 것으로 간주되기 때문에 bandwidth를 낭비한 것으로 생각할 수 있다. 그래서 BIOS에서는 비효율을 줄이기 위해 prefetcher를 껏다 키기도 한다.
'컴퓨터 > 컴퓨터구조특론' 카테고리의 다른 글
| [ACA] Instruction-level Parallelism (2) (0) | 2020.12.28 |
|---|---|
| [ACA] Instruction-level Parallelism (1) (0) | 2020.12.26 |
| [ACA] 캐시 메모리의 인덱스로 중간 비트를 사용하는 이유 (0) | 2020.04.14 |
| [ACA] Improving Cache Performance (0) | 2020.04.13 |
| [ACA] Memory Hierarchy and Caches (4) (0) | 2020.04.12 |