Paper Link: https://arxiv.org/abs/1909.12579
Introduction

이전 리뷰에서는 Pruned Structure를 어떻게 하면 빠르게 수렴시킬 수 있고, 높은 성능을 낼 수 있을까에 대한 이야기를 하였습니다. "Lottery Ticket Hypothesis(LTH)"이후의 후속 논문들을 살펴보면 대개 Pruned Structure를 어떻게 하면 잘 얻을 수 있을지, 이 Structure는 어떤 성격을 갖고 있는지, 그리고 Winning Ticket은 어떻게 얻을 지와 같은 이야기들을 합니다. 하지만 여기서 필연적으로 '학습'이라는 과정이 필요합니다. 여기서 고민해볼 필요가 있습니다. 과연 '학습'은 Pruned Structure를 얻는 데 있어 꼭 필요한 걸까요? 답은 "No" 입니다. ICLR 2019에 발표된 SNIP을 살펴보면 별다른 학습 과정없이 좋은 성능을 갖는 Pruned Structure를 얻는 것에 성공했습니다. 하지만 이전의 연구들을 보면 모두 학습 이후에 pruning을 진행했는데요. 학습 없이도 좋은 structure를 얻는 데 성공했다면 학습이 pruning에 영향은 무엇일까요? 학습과 pruning사이 관계에 주목할 필요가 있어보입니다.
본 논문에서는 학습이 Pruned Structure Space를 줄임을 실험적으로 보이며, 초기화 단계에서 Channel Importance로 Thresholding하여 Pruned Structure를 찾은 뒤, 학습시키면 더 나은 성능을 갖는 Structure를 기존의 방법들 보다 10-100배 빠르게 찾을 수 있음을 보여줍니다. 우선, Pruning에서 학습을 하는 것이 어떤 영향을 끼치는지부터 살펴보겠습니다.
Rethinking Pruning with Pre-Training

이들은 네트워크를 서로 다른 랜덤 시드를 사용해서 프루닝을 했다. 그리고난 뒤에 각 레이어에 남아있는 채널의 개수를 original network의 채널 개수로 나누어 각 레이어마다 할당되는 값을 만들었고 이들을 concat하여 벡터를 만들었다. 즉, 프루닝 이후에 남은 채널의 비율에 해당하고 네트워크에 대응되는 벡터를 하나 만든 것이다. 그러면 이제 네트워크에 대해 벡터가 두 개가 만들어졌는데, 이걸 각 epoch과 random seed마다 만들어서 correlation coefficient를 계산하고 matrix를 만들어준 것이 위의 피규어다. 보면 random seed를 달리 하더라도 epoch을 늘릴수록 correlation이 커지는 걸 알 수 있는데, 이는 pre-training이후에 다른 방법으로 pruning을 적용해도 얻을 수 있는 네트워크 구조가 유사하다는 것으로 해석할 수 있다. 논문에서는 학습을 진행함에 따라 pruned structure space 줄어들고, potential performance를 제한할 수도 있다고 말한다. 최근 'Lottery Ticket Hypothesis'나 'Rethinking value of the network pruning'과 같은 논문에서 pruning이후에 얻을 수 있는 trained-weight보다는 network architecture가 중요하다고 여겨지고 있다. 그런데 pretraining을 많이 할수록 유사한 network architecture밖에 얻을 수 없다면 이는 불필요한 과정이라고 생각할 수 있다. 이는 위의 피규어를 확인하면 알 수 있다. 피규어에 나온 matrix의 대각 성분이 모두 1이라는 점이 재밌다. Random Weights에서 direct하게 pruning을 하면 값이 제각각인 걸 확인할 수 있는데, 저자들은 이 관찰로 random weights에서 pruning을 하는 것이 훨씬 다양한 pruned architecture를 얻을 수 있음을 시사하며, 초기화 단계에서 channel pruning을 하는 방법을 제시했다.
*이 챕터의 모든 실험은 'Learning efficient convolutional networks through network slimming'으로 진행됐다. 다른 pruning technique으로 안될 수도 있잖아? 싶어서 다른 테크닉으로도 해봤냐고 저자에게 메일을 보내봤는데, 해보지는 않았다고 한다. 아마 될 것 같다는 메일만 받았다..

Pruning from Scratch
이들은 초기화 단계에서 가중치 업데이트 없이 channel importance를 학습하여 pruning하는 방법을 제안했다. f(x;W,/alpha)라는 신경망을 하나 생각해보자. 여기서 x는 input sample, W는 trainable parameters, /alpha는 model structure다. model structure는 주로 NAS 연구에서 종종 이야기하는 파라미터인데 operator types, dataflow topology, layer hyperparmeter types을 말한다. 이때 각 레이어마다 효율적으로 channel importance를 학습하기 위해 scalar gate values /lambda_j를 channel dimension에 맞게 뒀다고 한다. 그러면, gate value는 해당 레이어의 채널이 뱉는 output에 곱해지는데, 이때 gate value가 작다면 이에 대응되는 channel output을 supperess하는 효과를 가져와 pruning effect를 기대할 수 있다. 이들의 objective function for channel importance는 다음과 같다.
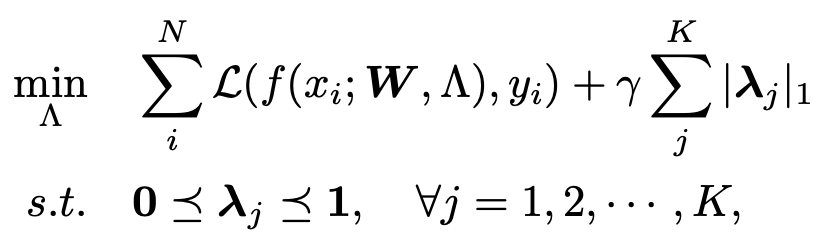
/y_i는 input에 대응되는 정답 라벨, L은 cross-entropy loss, /gamma는 balance factor를, 대문자로 쓰인 lambda는 각 레이어마다 있는 scalar gate values lambda를 모아놓은 집합을 뜻한다. 여기서 저자들은 두 가지 차별점이 있다고 하는데, 이는 다음과 같다.
1. Channel importance를 학습하는 중에, 모델의 다른 파라미터를 업데이트하지 않았다.
2. Pre-trained weight없이, 초기화 단계에서 pruning을 진행했다.
이제 이를 최적화하기 위해서는 sub-gradient method를 사용했다. Sub-gradient method는 convex지만, non-smoothd인 함수를 최적화하기 위해 사용되는 방법이다. 그런데 obj function의 lambda에 별다른 제약없이 naive L1-norm을 사용했기 때문에 좋은 pruned structure를 얻을 수 없다고 생각했다고 한다. 그래서 여기다가 하나의 제약 조건을 추가했다. Sparsity ratio를 근사하기 위해서 모든 게이트의 element-wise mean을 사용했고, 이걸 미리 정의된 sparsity ratio로 push하기 위해서 square-norm을 사용했다고 한다. 이는 다음과 같다.

여러 번 실험을 돌려봤더니, 이 조건 없이 pruned structure를 찾아낸 것보다 나은 성능을 보이는 pruned structure를 얻을 수 있었다고 한다. 위에 식을 통해서 최적화를 하다보면, pruning을 할 target gate가 여러 개가 될 수도 있는데, 최종적으로 pruning을 할 gate는 가장 높은 validation accuracy를 보이는 것으로 골라냈다고 한다. 그리고, 최적화된 gate value를 골라내면 thresholding을 했다. 이때 network slimming과 다른 점은, network slimming에서는 parameter size에 제약을 걸어서 thresholding을 했는데 얘네는 FLOPS에 제약조건을 걸어서 thresholding을 했다고 한다. 이때 global threshold는 pruned structure가 FLOPS contraint를 만족할 때까지 이진 탐색을 통해 찾았다고 한다. Pruned structure를 찾는 탐색 전략은 다음과 같다.

Target FLOPS을 맞추기 위해서 thresholding하는 걸 반복적으로 바꿨다고 볼 수 있다.
이외에도 Channel pruning을 위해서 channel expanxsion이라던가, 'Rethinking value of network pruning'에서 실험한 budget training을 해본다던가, channel gate의 위치를 network slimming에서 하듯이 batch normlization에 붙여서 해본다던가 하는 등의 실험을 했다고 한다.
Experiment


실험은,, 대개 자기네들 성능이 더 좋다는 이야기고.. 앞서서 training이 pruned structure similarity를 높인다고 했으니 이에 대한 결과를 다음과 같이 보였다.

Training을 하면 시드를 바꾸더라도 채널 개수가 일정했는데, 이 방법을 이용하면 채널 개수가 비교적 다양해진다. 즉, 다양한 pruned structure를 얻을 수 있었다는 이야기다. 그러면 다양하게 얻은 pruned structure에 따른 model size나, FLOPS은 어떻게 되는지 궁금하다. 애초에 contraint를 걸어서 찾은 거기 때문에 FLOPS은 다들 비슷하게 나올 거 같긴한데.. 신기한 결과다.
논문 말미에는 'Lottery Ticket Hypothesis'와 이를 비교하는 부분이 있다. Lottery ticket에서는 pruned model이 origianl model과 비슷하거나 더 나은 성능을 보기 위해서는 original model의 weight으로 초기화를 해야된다고 말하는데, 저자들은 그렇게 안해도 되고 random initialize하는 게 더 나은 성능을 보였다고 이야기한다. 음,, 뭔가 lottery ticket읽을 때 실험 과정에서 휴리스틱이 너무 많이 들어가서 이게 정말 되는 건가 싶었고, 직접 실험해볼 때도 더 나은 성능 보이는 게 휴리스틱없이는 쉽지 않았는데,, 이 논문을 이후로 lottery ticket에 반대되는 주장을 하는 논문들이 나올까? 기대된다.