Paper Link: https://arxiv.org/abs/1810.02340
Github: https://github.com/namhoonlee/snip-public
Introduction
본 논문은 ICLR 2019에서 발표된 weight pruning 논문입니다. 본 논문에서는 기존의 pruning 기법들이 휴리스틱에 근거한 hyperparameter를 사용하거나 iterative하게 pruning하는 것을 지적하며, training이전에 connection sensitivity를 계산하여 이를 기반으로 single-shot pruning하는 것을 제안합니다. 실제로 origianal network보다 efficient한 subnetwork를 얻기 위해서는 꼭 학습이 필요한 것인가? 그리고, 프루닝 이후 얻은 가중치들이 중요한 것들인가?에 대해서 이를 반박하는 최근 연구들이 많습니다. ICLR2019에 발표된 'Rethinking the value of network pruning'에서는 프루닝 이후의 모델을 학습시킬 때 여러 가지 학습 방법을 통해서 애초에 큰 모델을 학습시킬 필요가 없다는 것, 큰 모델에서 특정 기준을 통해 골라진 가중치는 작은 모델에게 필요 없다는 것, 마지막으로 프루닝을 통해 얻은 네트워크 구조 자체가 가중치 값보다 중요하다는 것을 실험적으로 보입니다. NIPS2019에 발표된 'Lottery ticket hypothsis'의 경우에도 프루닝 이후의 모델을 학습시킬 때 남아있는 가중치를 사용하지 않고, 초기화하였을 때 몇가지 휴리스틱을 첨가하면 빠르게 수렴하는 것을 보이기도 했습니다. AAAI2020에 발표된 'Pruning from scratch'의 경우에도 이와 비슷한 맥락의 이야기를 합니다. 여튼, 프루닝에 대한 사람들 생각이 조금씩 바뀐다는 걸 확인할 수 있습니다.
Neural Network Pruning
Neural net pruning 관련해서는 모두들 neural net이 overparametrized 되어 있다고 생각합니다. 그리고 이것보다 적은 parameter로 구성되어 있으면서 퍼포먼스는 더 좋은 small network를 얻을 수 있습니다. 그래서 하고 싶은 건 이제 large network의 accuracy는 유지하면서 small network를 얻고 싶은 건데 이걸 최적화 문제로 바꾸면 다음과 같습니다.

여기서 이제 network를 sparse하게 해주기 위해서 penalty term을 넣는다던가, saliency를 기반으로해서 redundant parameter를 없앨 수 있습니다. 그런데 보통 penalty term을 넣는 방법은 saliency 기반의 방법보다 underperform하거나, 퍼포먼스를 얻기 위해서는 penalty term에 대한 hyperparameter tuning이 필요합니다. Saliency를 기반으로 pruning하는 것 중에 제일 대표적인 건 norm-based criterion으로 일정 threshold 이하의 parameter들을 없애는 거랑 loss의 Hessian을 계산해서 낮은 Hessian value를 갖는 parameter를 없애주는 겁니다. 그런데 norm-based criterion은 너무 휴리스틱 기반으로 다루는 단점이 있고, Hessian을 계산하는 건 small network을 다루는 경우에는 괜찮지만 large network에 대해 계산하는 건 complexity때문에 계산 시간이 너무 오래 걸립니다.

여튼 iterative pruning을 해줘야 하고, 위의 pruning 방법들은 model architecture가 달라지면 적용하기 힘들어지는 확장성 문제가 있기 때문에 본 논문에서는 training이전에 connection sensitivitry를 측정해서 loss를 direct로 최적화하여 pruning하는 single-shot pruning을 보였습니다.
Single-Shot Network Pruning Based on Connection Sensitivity
논문에서는 위의 최적화 문제를 다음과 같은 문제로 변형을 하여, loss에 대한 최적화를 진행하였습니다.

여기서 weight과 connectivity를 나타내는 항은 분리돼있는데, 여기서 아이디어를 얻어서 각각의 weight의 connectivity에 따라 loss의 변화율을 계산하였습니다.
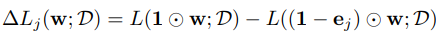
이 식을 계산하면 connection j가 loss에 얼마나 영향을 미치는 지 알 수 있습니다. 하지만, 이 식을 계산하려면 weight의 갯수만큼 forward pass를 계산해야하기 때문에 large network의 경우에는 많은 컴퓨팅 소스를 필요로 하고 비효율적입니다. 그래서 이걸 c에 관해 derivative를 계산할 수 있다면 framework에 있는 automatic differentiation을 이용해 쉽게 계산할 수 있을 것입니다. 그래서 c에 관한 loss의 derivative를 다음과 같이 구해줍니다.
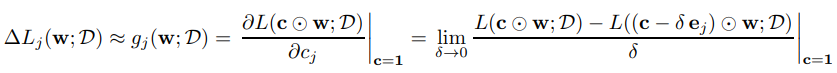
그런데 여기서 c는 0과 1만을 값으로 갖기 때문에 미분이 불가능합니다. 그래서 c에 관한 제약조건을 적당히 완화하여, 1 근방에서 적당히 delta만큼 interval을 잡아 derivative를 계산해주었습니다. 이렇게 돼면 모든 connection에 대해서 한번에 loss의 변화율을 구할 수 있습니다.
만약 특정 connection이 loss에 영향을 많이 미친다면 변화율이 클 것이고, 그렇지 않다면 작을 것입니다. 이에 기반해, connection j에 대한 sensitivity는 다음과 같이 정의합니다.
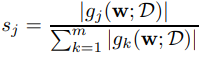
여기서 sensitivity가 크다면 connection j는 중요한 것일 거고, 작다면 중요하지 않은 것이겠죠. 그래서 만약에 sparsity level을 k로 잡게되면 sensitivity가 높은 상위 k개의 connection만 남기고 나머지는 모두 pruning해줍니다. 이걸 이용하여 indicator variable c를 좀 더 정확하게 정의하면 다음과 같습니다.

SNIP의 알고리즘은 다음과 같습니다.

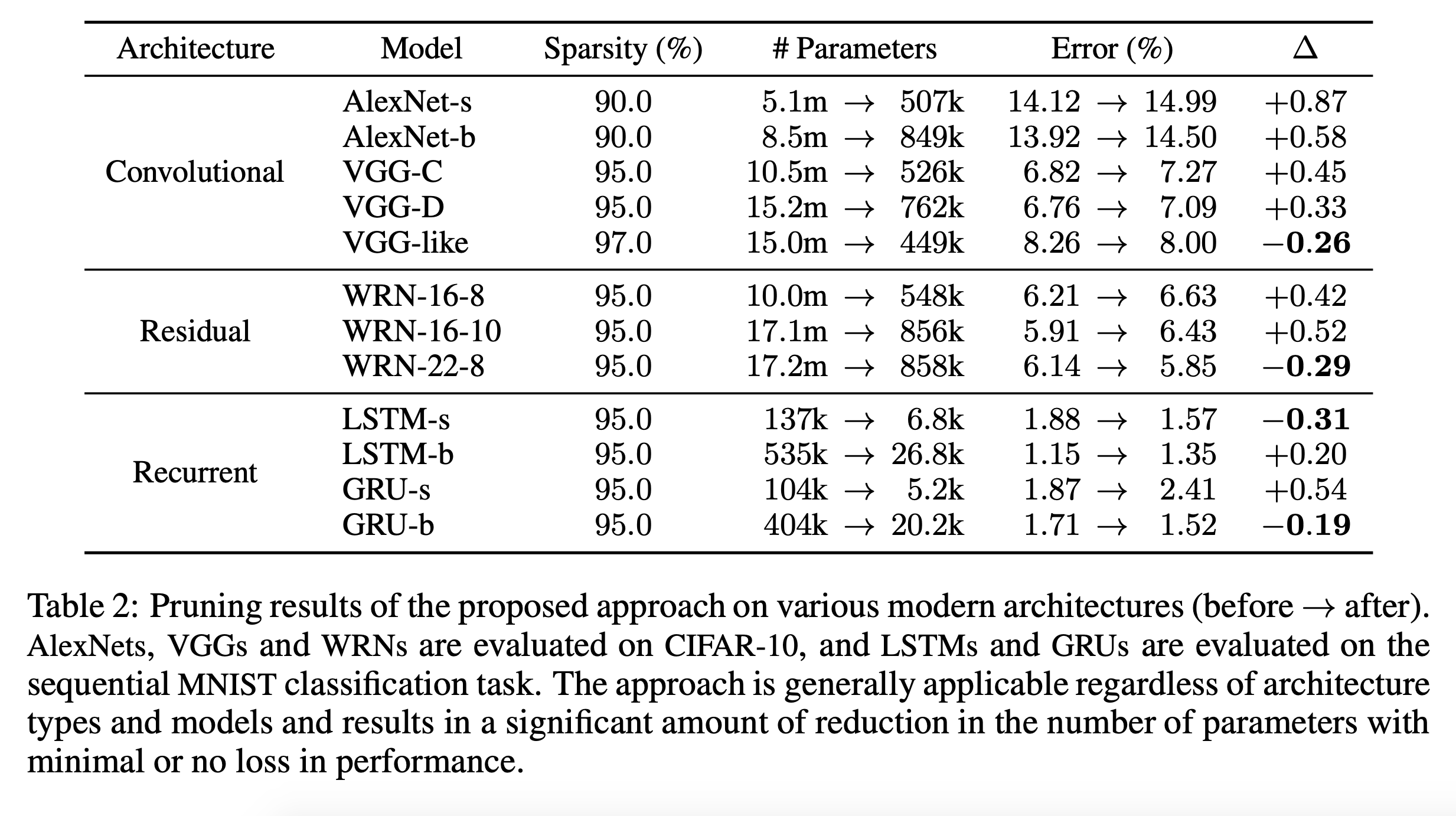
Experiment